What is a constraint?
The basic premise of SDV is to use AI to learn patterns from relational databases. This allows you to create a synthetic database that has similar properties as the original database. Like most AI-based systems, SDV’s default algorithms create the synthetic data probabilistically. This means that they learn patterns such as the distributions of each column and correlations between different columns. Synthetic data creation is a probabilistic process based on these patterns. Since SDV is designed to work for multi-table databases, it also comes with built-in knowledge about major database definitions like primary keys and foreign key references. All of this results in synthetic data that is correctly structured and high quality out-of-the-box.- Correctly structured means that it follows the same database structure as the original database. For example, all synthetic databases have referential integrity and the same column/row structure as the original database.
- High quality means that the probabilistic patterns are generally the same. The synthetic data generally has similar distributions and correlations as the original data.
Using constraints in SDV
Many types of rules follow a similar template. For example:- Within a financial services dataset, there may be a rule that an account creation date must occur before transactions are made.
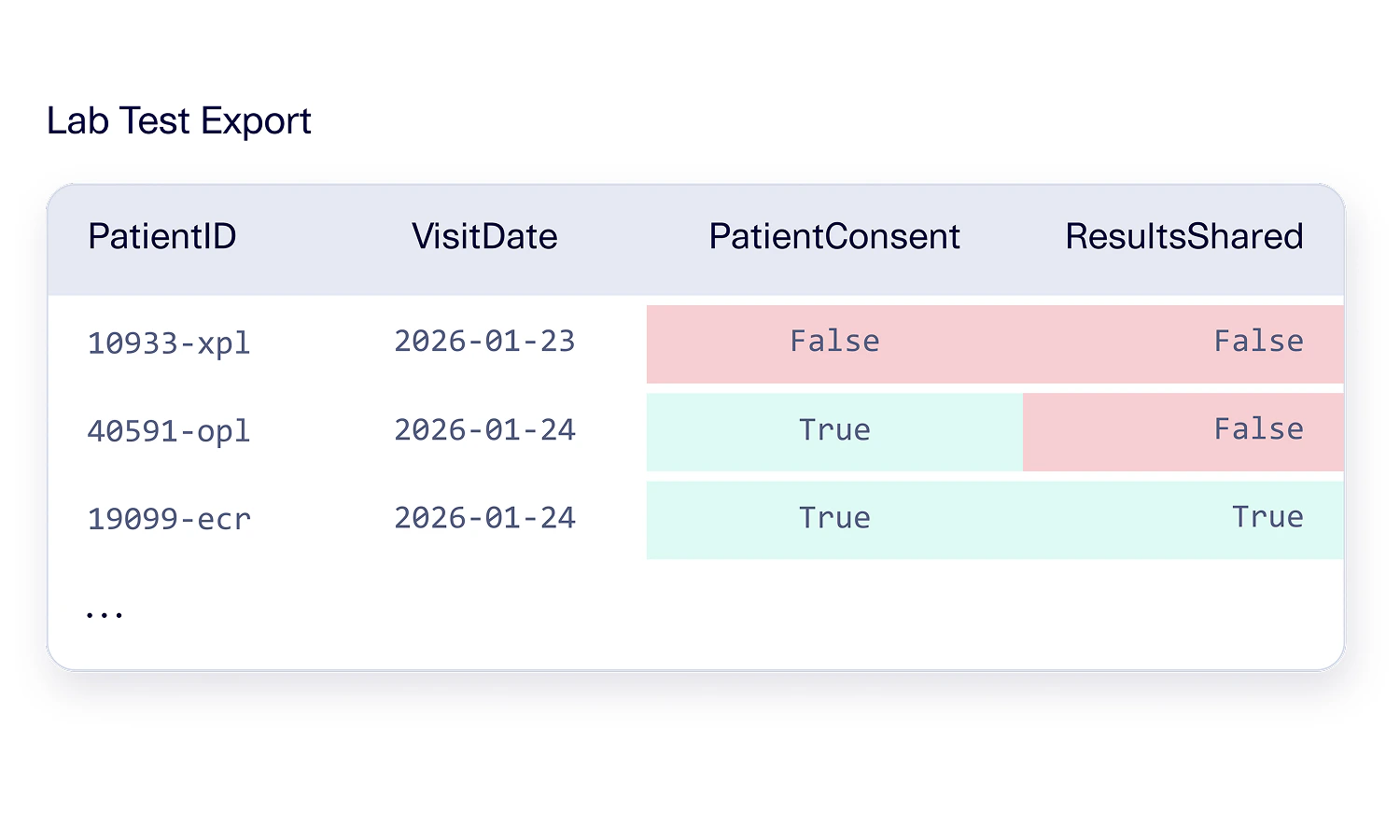
- Within a healthcare dataset, there may be a similar rule that a patient’s date of birth must occur before any patient visits can occur.
The CAG bundle also includes a feature that is useful for enterprise data: Automatically detecting constraints in a database, which is useful when you may not know all the intrinsic rules governing a particular dataset.
Why do constraints exist?
Constraints are an essential feature for creating valid enterprise-grade synthetic data. Our research has shown that a majority of enterprise-grade datasets carry at least one constraint that can be important when creating synthetic data. In this section, we’ll go through some important reasons why constraints exist and some examples of each.1. Universal invariants
Some constraints arise as a result of universal rules. These rules are always true of the world regardless of any particular industry or domain that the database resides in. They represent more fundamental truths of the universe. The most common example of this is the concept of time. The invariant is: Time must always move forward. This typically manifests as constraints between different date attributes in a database. For example:- An item must be crated before it can take any action (e.g. a person must be born before visiting a practitioner, or an account created before making a transaction)
- An interval’s start date must always occur before the end date (e.g. an insurance policy start/end dates, or a hospital patient’s intake/discharge dates)
- And so on.
2. Industry concepts & regulations
Constraints can also arise from industry-specific definitions, which act as invariants within that specific field. As the legal and compliance framework matures within an industry, this results in constraints that look similar between databases in the same industry. Within the financial services industry, one example is the Know Your Customer (KYC) regulations which are part of a global anti-money laundering effort. This regulation includes mandates such as collecting identifying information and verifying it. As a result, a financial services database might have a constraint that anyone within an account balance of over $10,000 must be verified.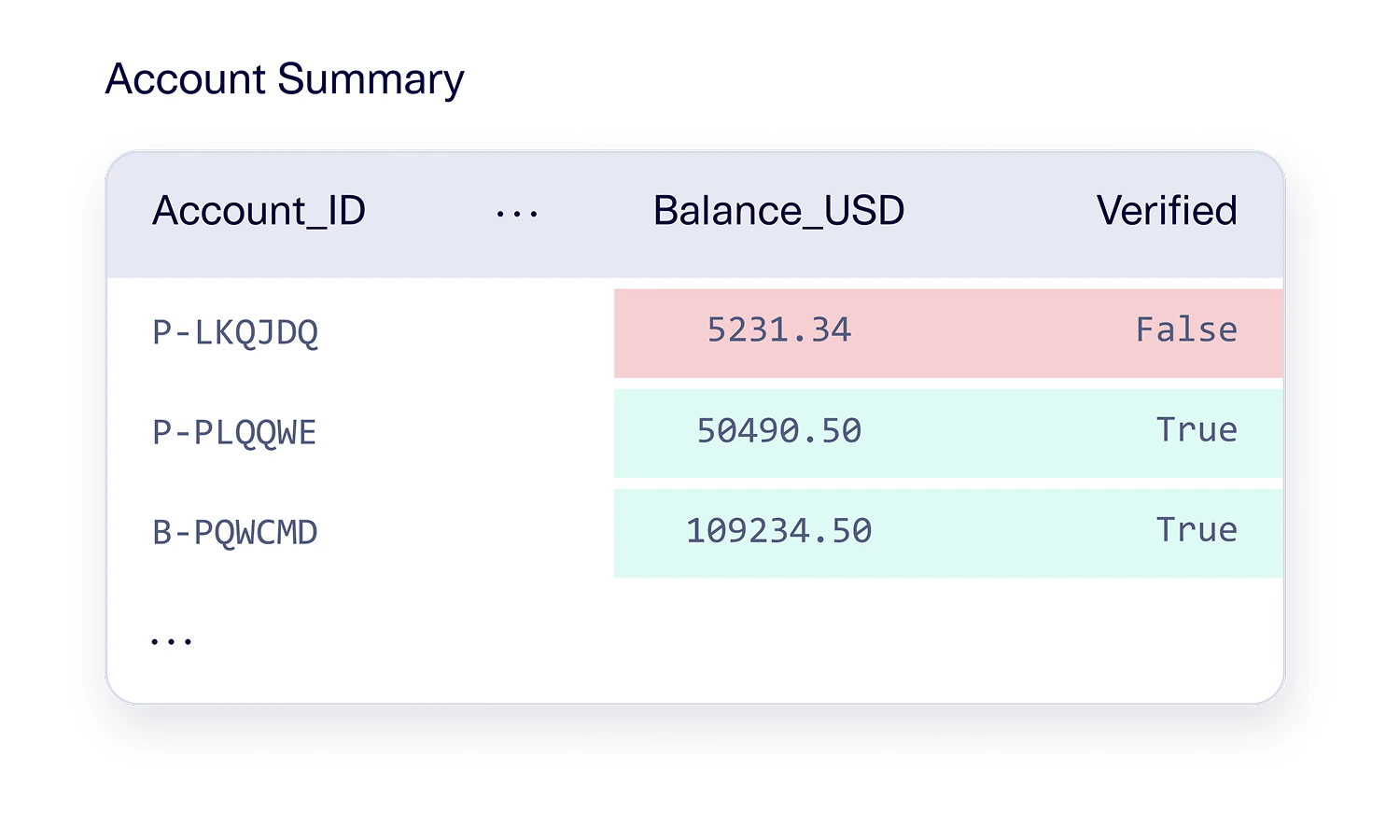
3. Organizational standards & workflows
Even within the same industry, an organization has control over its internal processes and workflows. These can manifest as more nuanced rules within a dataset – but the overall logic still falls under one of the predefined classes. One example is a high-amount insurance claims process that triggers a manual review. When triggered, the insurance claim must follow a chain of events from being submitted, to being reviewed, to being approved or denied. Within a particular organization, it may not be possible to render an automatic decision without a review.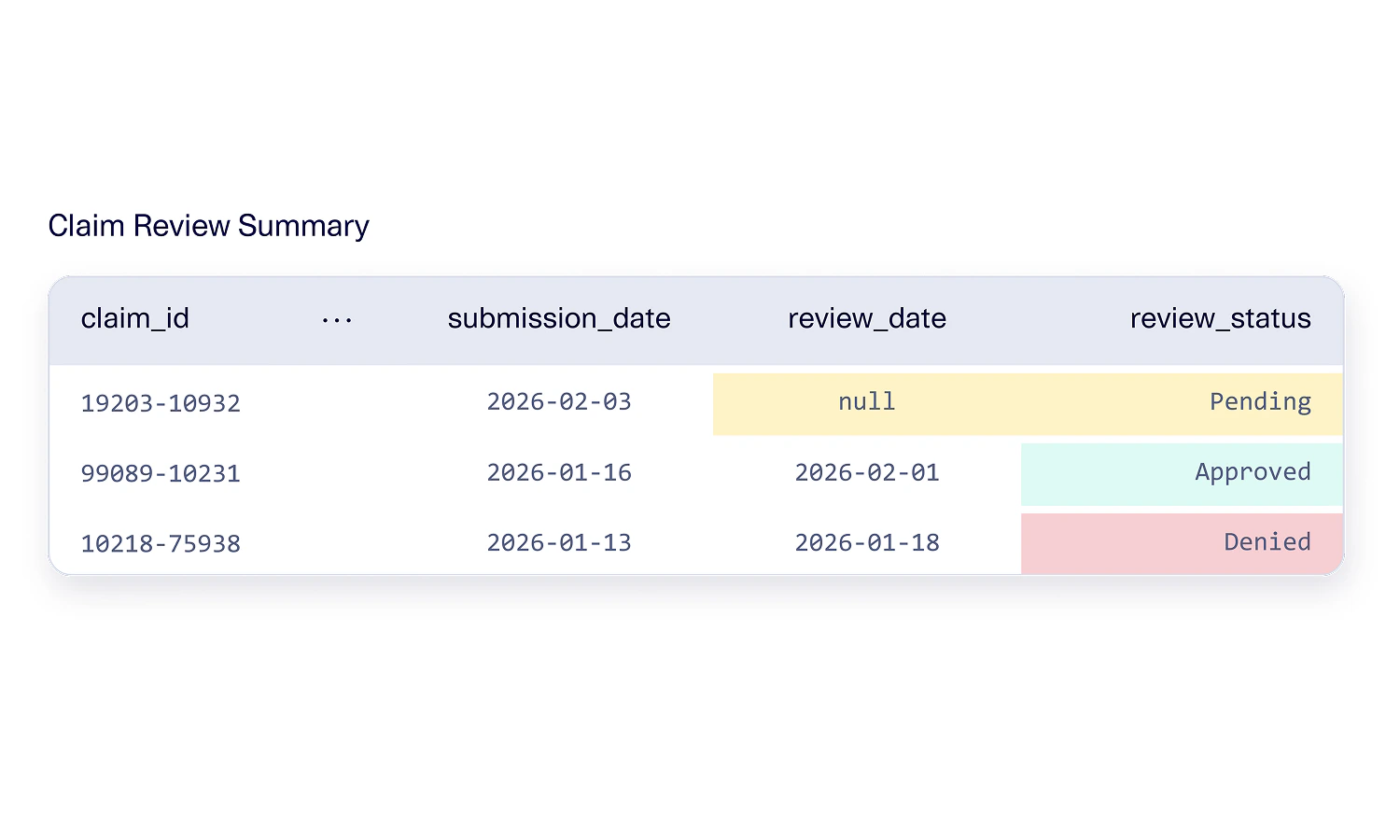

4. Database system design
Constraints can also arise as a result of explicit decisions that are taken by the engineering team when designing the database system. Database design principles may stipulate the “proper” way to design a database schema with zero redundancy and perfect primary/foreign key connections. But system designers also factor in other organizational needs such as performance optimization, ease of maintenance, and speed of implementation. Some decisions can result in additional database context logic that the system designers define and that applications assume. For example, a financial services database may redundantly store information about each account in the transactions table, even though it’s already available in the accounts table. This may be done with the explicit purpose of optimizing performance for applications that would otherwise need to frequently look up the information. However, it creates a rule that the data must be synchronized between the tables.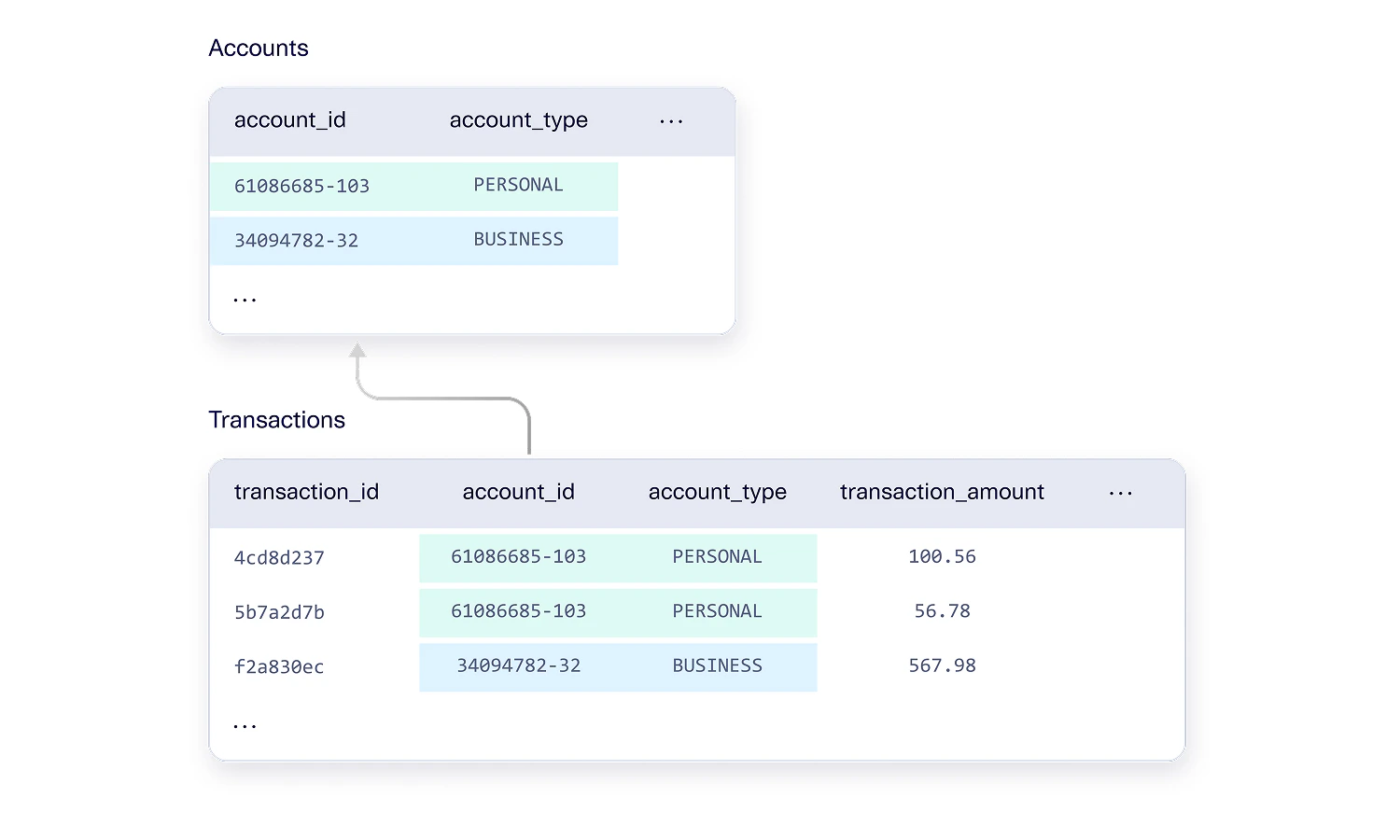

Takeaways
The table below summarizes different different types of rules, and how you can supply constraints to SDV to adhere to those rules.| Reason for constraint | Examples | Predefined SDV classes |
|---|---|---|
| Universal invariants |
| Inequality (for both) |
| Industry concepts & regulations |
|
|
| Organizational standards & workflows |
|
|
| Database system design |
|
|